CRAT - A PTX to PTX compiler that enables register allocation.
CRAT, which is the abbr. of Coordinated Register Allocation and Thread-level parallism, is a PTX to PTX compiler which enables register allocation at PTX-level. With CRAT, researchers are able to perform register study on PTX-based tools, like simulator.
Framework
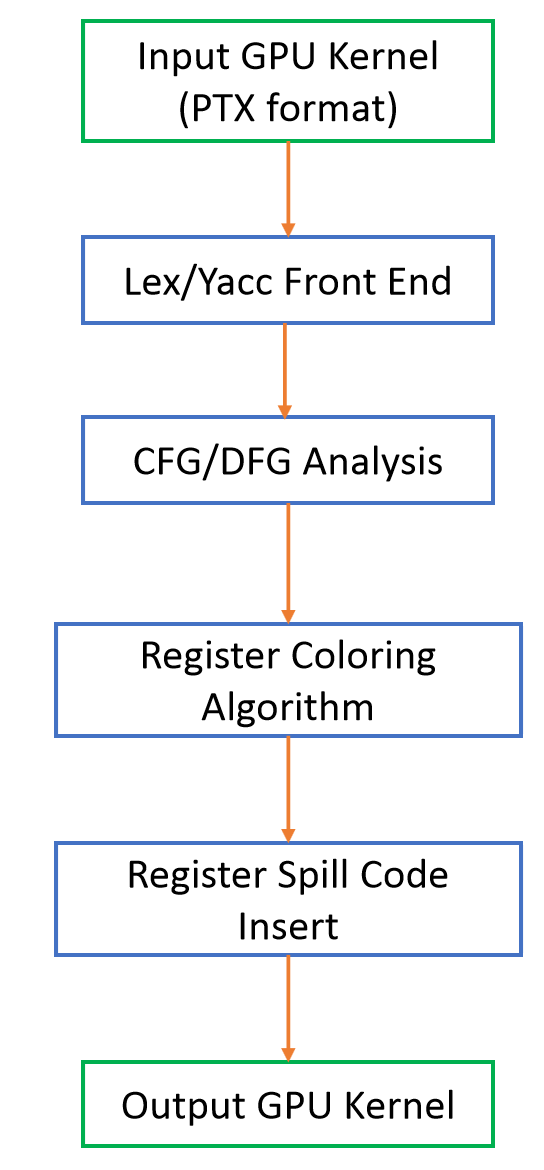 The framwork of the CRAT register allocator is shown in the right figure. The input of CRAT is the GPU kernel in PTX format and the output is also in PTX format. We use the Fermi PTX format.
The framwork of the CRAT register allocator is shown in the right figure. The input of CRAT is the GPU kernel in PTX format and the output is also in PTX format. We use the Fermi PTX format.
The register allocator is composed of four main compoments:
1) The first is a Lex/Yacc front end, which reads the PTX instruction stream and transform it into a internal representation of PTX code.
2) The second component performs control-flow graph (CFG) and data-flow graph (DFG) analysis on the internal representation.
3) The third component performs the register color alogirithm, which determines which variables are placed in the register file and which variables are placed in the local memory.
4) The forth component inserts spill code when register spilling happens.
Overall, CRAT register allocator is a "simple" compiler.
Tutorial
You can download a tutorial in the left navigation bar. The tutorial tells you how to intergrate the regsiter allocator into GPGPU-Sim as example and briefs the code structure to facilitate further development.
We suggest developers should first learn some basic knowledge about compiler, both front-end and back-end. It is also a good chance for you to start a simple compiler project as the CRAT register allocation is pretty simple.
Download
To get the download link, please click the Download button in the left navigation bar and fill the form. NOTE that we do not set any limitation to your application, any submitted form that contains real information (apparently) will be approved.
Reference
If you are using CRAT in research projects, please cite:
[MICRO-48] Xiaolong Xie, Yun Liang, Xiuhong Li, Yudong Wu,Guangyu Sun, Tao Wang, Dongrui Fan, "Enabling Coordinated Register Allocation and Thread-level Parallelism Optimization for GPUs", 2015 48th International Symposium on Microarchitectiure(MICRO).